BLR Neighborhood Explorer
A data-driven neighborhood comparison engine for Bengaluru
The problem
Moving to a new city is painful. Existing tools are outdated, scattered across 5 tabs, or behind paywalls. You need one place to understand neighborhoods — livability, rentals, amenities, commute times, weather — before signing a lease.
How it works
- —Aggregates 4+ live data sources: NoBroker rentals, Overpass API (OSM), OpenWeatherMap, custom livability scoring
- —Scores 100+ Bengaluru neighborhoods algorithmically: proximity to schools, hospitals, supermarkets, commute zones
- —Renders interactive maps with MapLibre GL — click any neighborhood to drill into rental listings and scores
Architecture
live sources
nightly cron
PostgreSQL
REST
frontend
Stack
Fitness Progress Coach
A Telegram-native AI coaching agent that knows your training history
The problem
Generic fitness apps don't know your programme. Manually tracking sets and weights is tedious, and none of it connects to coaching that actually references what you did last week. There's no tool that combines natural language logging with contextual AI feedback based on your specific history.
How it works
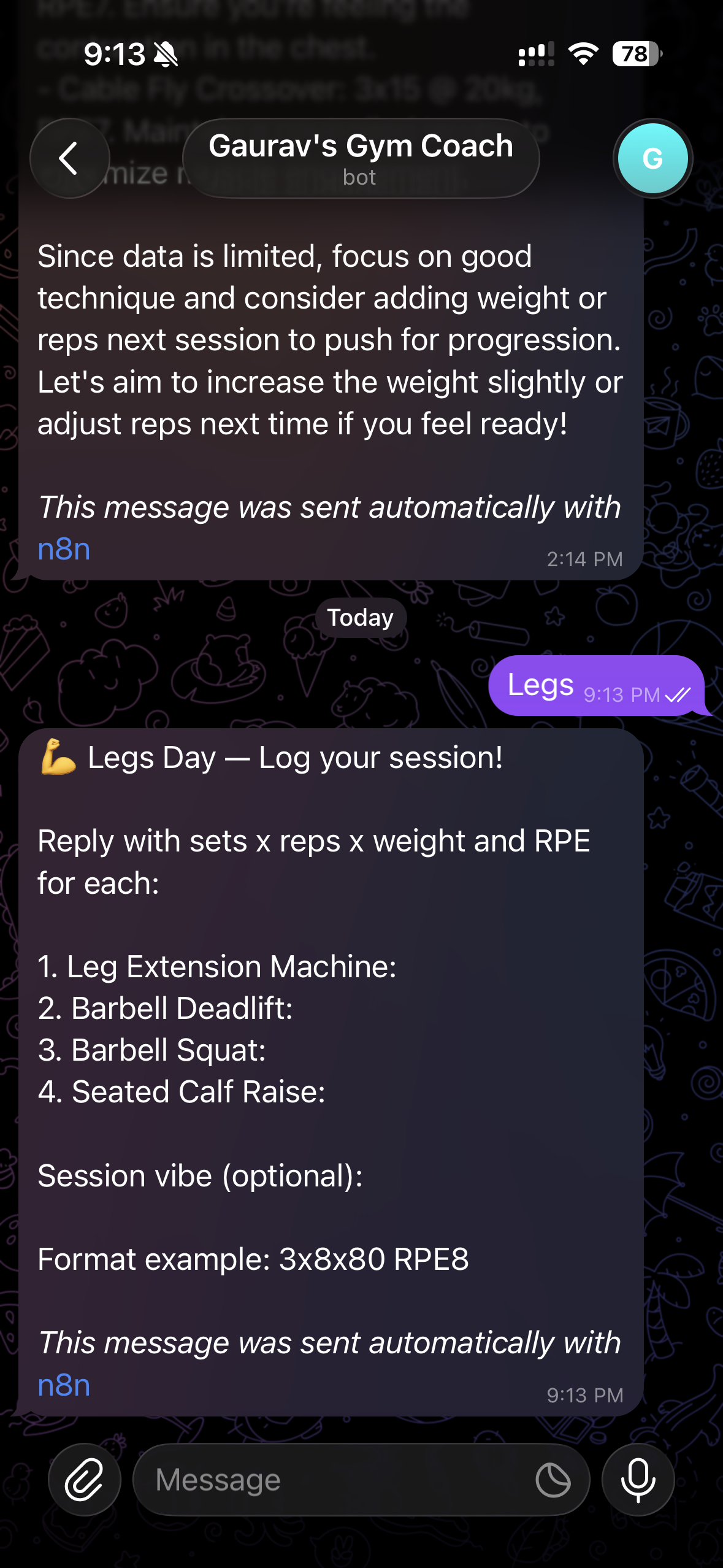
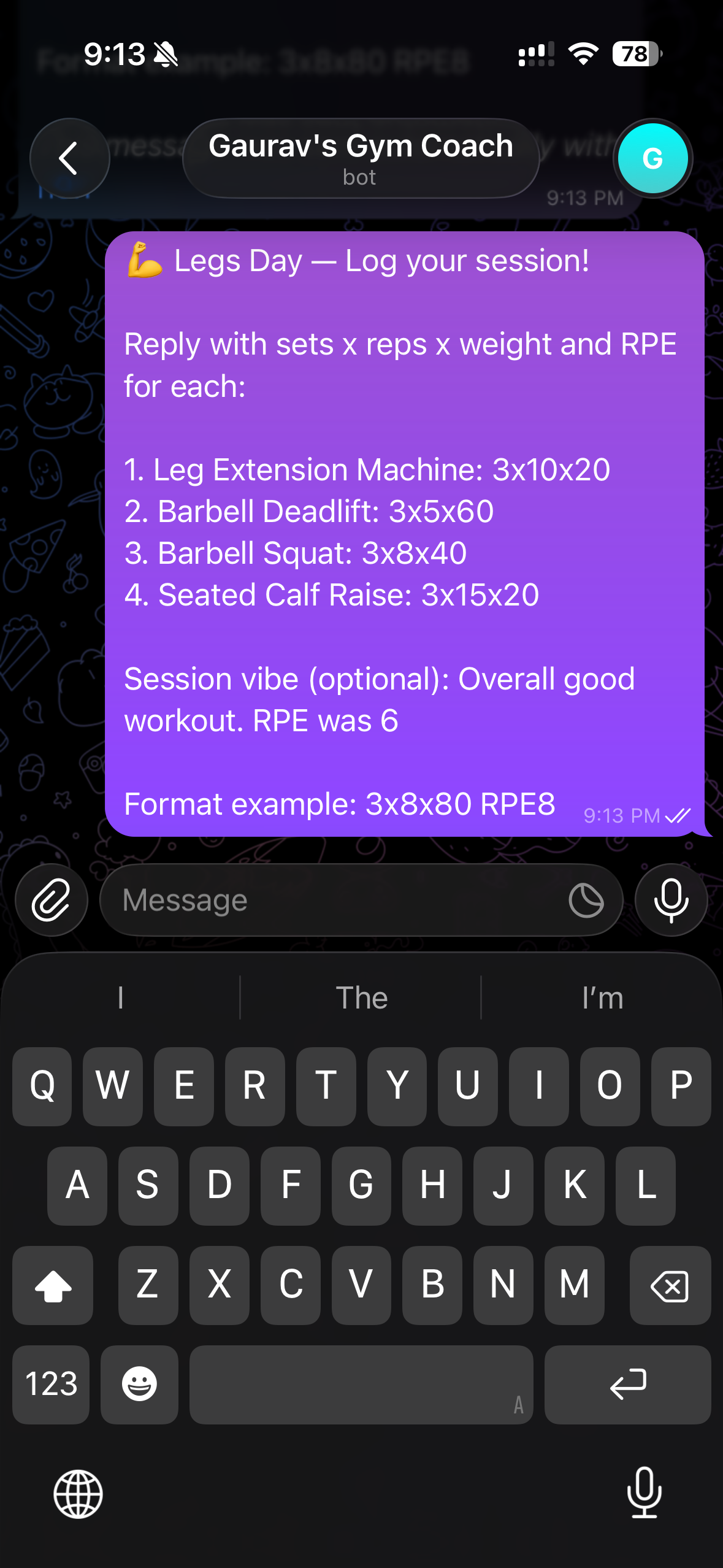
- —Text a keyword on Telegram (chest · back · shoulder · legs) and receive your pre-filled workout template instantly
- —Fill in sets, reps, weight, RPE and reply — a code node parses the log and writes every exercise as a row in Google Sheets
- —GPT-4o-mini fetches your last 4 sessions per exercise from Sheets, detects plateaus and PRs, and sends coaching feedback as Marcus — a direct, data-driven coach persona
 →
→ →
→
Architecture
trigger
webhook + switch
keyword / workout
extract + log
GPT-4o-mini
feedback
Stack
For Job Hunt
Automated job search assistant for HR/talent roles in India
The problem
Job hunting in India means manually checking 5+ job boards every day — Naukri, LinkedIn, Indeed, SmartRecruiters, Workday. That's 2–3 hours of repetitive, soul-destroying work before you've even applied to anything.
How it works
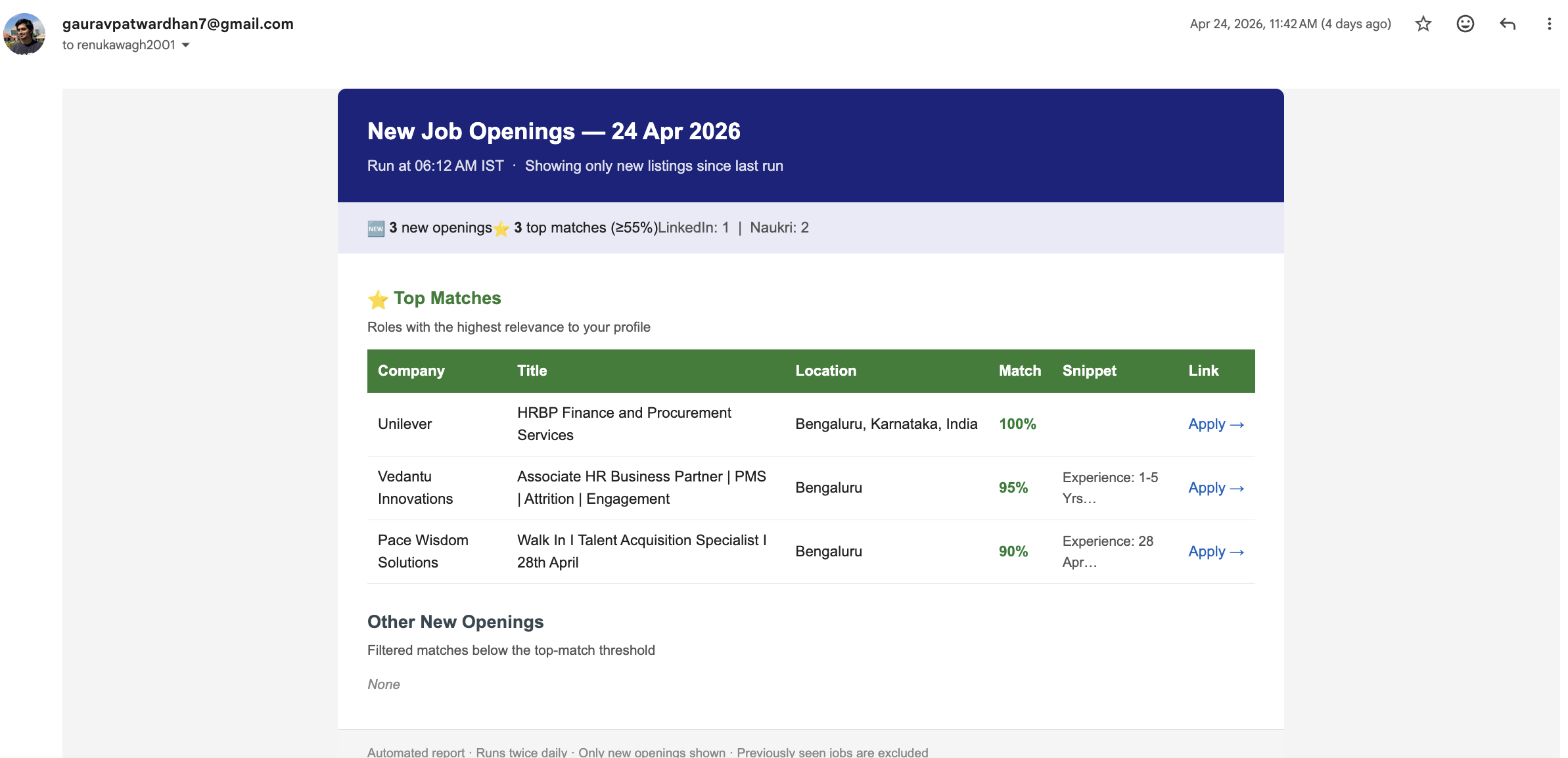
- —Scrapes 5+ job boards daily using Selenium (JS-heavy sites) and BeautifulSoup
- —Filters results by resume keywords, location preference (Bengaluru/Remote), and experience level
- —Ranks output: 60% keyword match + 40% GPT-3.5 semantic confidence score
Architecture
job boards
scraping
Supabase + GPT-3.5
ranked by relevance
9 AM + 6 PM IST
Stack
Claude Token Efficiency
Honest token analytics for Claude Code — cache reuse, context utilization, session stats
The problem
Claude Code writes detailed session data to local JSON files — but nobody reads them. You don't know your cache hit rate, how much of your 200K context window you're actually using, or whether your session habits are efficient. If you can't measure it, you can't improve it.
How it works
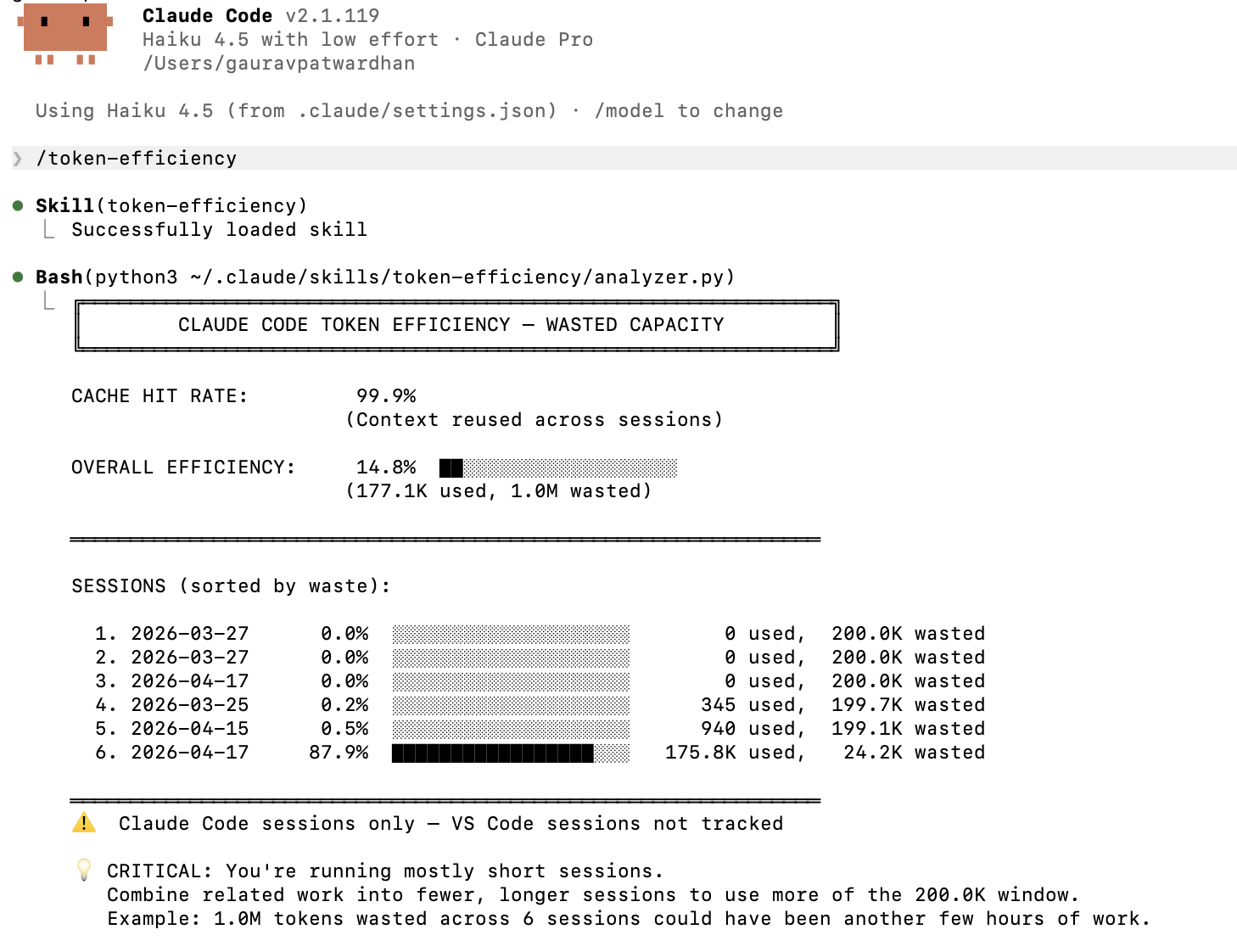
- —Reads 3 local ~/.claude/ files: stats-cache.json, session-meta/*.json, and facets/*.json — no API calls, no auth, nothing leaves your machine
- —Computes cache hit rate (% of tokens served from cache) and capacity utilization (% of 200K session window used on average)
- —Surfaces session statistics: total sessions, min/max/average tokens, and a recent activity breakdown with per-session detail
Architecture
local ~/.claude/ files
zero dependencies
console report
Stack